






📌 이 정보 안 보면 손해!
블로그별 꿀팁 모음집, 한 번에 보기!

📋 목차
화웨이가 AI 서버 시장에서 다시 한번 주목받고 있어요. 어센드 910C 기반의 대형 AI 서버 시스템 ‘클라우드 매트릭스 384’는 성능 면에서 엔비디아의 GB200 서버와 견줄 수 있다는 분석이 나왔답니다.
이 분석은 단순한 칩 성능을 넘어, 시스템 전체 네트워킹 구조, 메모리 대역폭, 냉각 방식, 그리고 확장성까지 포함한 통합적인 비교에서 비롯된 거예요. 특히 화웨이가 원래부터 강점을 가지고 있던 네트워크 설계력이 이번 AI 인프라 구축에서도 돋보였다고 해요.
제가 생각했을 때 이건 단순히 기술 스펙을 나열하는 문제를 넘어서, 미국과 중국의 AI 기술 전략 차이를 보여주는 아주 흥미로운 사례 같아요. 지금부터 한 섹션씩 자세히 알아볼게요!
👉 잠깐! 아직도 당신의 데이터가 안전하다고 생각하나요? 보안 확인 필수! 아래 버튼 눌러 바로 확인해봐요! 🔒
🚀 화웨이 AI 서버의 등장 배경

화웨이는 단순한 통신 장비 기업이 아니에요. 이미 수년 전부터 자체 AI 칩 개발에 집중해 왔고, 그 결과물이 바로 어센드 시리즈 프로세서죠. 그중에서도 ‘어센드 910C’는 화웨이의 최신 AI 칩으로, AI 학습 및 추론에 최적화된 성능을 보여줘요.
미국의 기술 제재 속에서도 SMIC를 통한 생산 또는 TSMC의 이전 생산분을 활용해 고성능 칩을 확보했고, 이번에 공개된 ‘클라우드 매트릭스 384’는 총 1184개의 어센드 910C를 연결한 거대한 서버예요. 이 서버는 단일 칩 수준을 넘어서, 대규모 병렬 연산을 위한 클러스터 기반의 시스템으로 완성됐답니다.
특히 중국 정부의 전폭적인 지원과 함께 화웨이는 AI 중심 기술 주도권 확보를 위해 칩뿐만 아니라 네트워킹, 냉각 기술, 메모리 통합까지 토탈 솔루션을 개발하고 있는 중이에요. 이 부분이 글로벌 경쟁에서 화웨이가 가지는 핵심 무기 중 하나랍니다.
또한 AI 생태계 전반에 걸쳐 자체 기술 내재화를 강화하고 있는데, 이는 기술 자립을 향한 강력한 신호이기도 해요. 반도체부터 네트워크 스위칭, 서버 아키텍처까지 자체적으로 확보하고 있다는 점은 화웨이의 진정한 위협 요소라 볼 수 있어요.
📌 어센드 910C 개요
| 항목 | 내용 |
|---|---|
| 칩명 | 어센드 910C |
| 제조공정 | 7nm (SMIC or TSMC) |
| 연결 수량 | 1184개 |
| 서버 시스템 명 | Cloud Matrix 384 |
이처럼 화웨이는 단순한 칩 성능이 아니라, 전체 시스템 설계 및 네트워크 최적화를 통해 엔비디아급 성능을 실현하고 있어요. 성능 자체보다 중요한 건 "엮는 능력"이라는 걸 잘 보여주는 사례죠. 🤖
📢 다음 세대 AI 서버 전쟁, 어디까지 갈까요?
👇 더 자세히 알아보고 싶다면 바로 아래를 클릭!
📌 미래 기술의 방향을 미리 알고 싶다면?
AI 시장의 다음 트렌드를 알고 싶다면 지금 확인하세요!
화웨이와 엔비디아의 경쟁 구도, 그 핵심을 공개합니다.
🧠 어센드 910C 아키텍처 분석

어센드 910C는 화웨이의 대표적인 AI 프로세서로, 트랜스포머 기반의 대규모 모델 학습에 최적화돼 있어요. 기본적으로 BF16 연산에서 최대 512 TFLOPS의 성능을 내며, 다양한 연산 타입을 유연하게 지원해요.
이 칩은 고속 메모리 통신을 위해 HBM2E를 탑재했으며, 다수의 NPU(Neural Processing Unit)가 병렬적으로 탑재되어 있어 대규모 매트릭스 연산에 강점을 보여줘요. 특히, 높은 연산 효율과 전력 대비 성능을 지향하는 구조로 설계됐답니다.
또한, 910C는 화웨이의 AI 프레임워크인 MindSpore와 최적화되어 있어요. 이는 칩 하드웨어에 맞춰 소프트웨어 스택을 조정한 구조이기 때문에 전체 학습 속도를 획기적으로 끌어올릴 수 있어요. 쉽게 말해, CPU와 NPU, 메모리 사이의 병목을 줄이고 최적 경로로 데이터를 전송하게 해 준답니다.
기존의 GPU와 달리, 910C는 하드웨어-소프트웨어 공동 최적화를 핵심으로 삼고 있어요. 이 구조 덕분에 작은 리소스로도 효율적인 대규모 학습이 가능하고, 중국 내부 AI 산업에서 자립 기반이 되는 원동력이 되었답니다.
🧩 어센드 910C 주요 스펙
| 구분 | 내용 |
|---|---|
| 연산성능 (BF16) | 512 TFLOPS |
| 메모리 | HBM2E, 128GB |
| 최적화 소프트웨어 | MindSpore |
| 제조 공정 | TSMC 7nm |
이 칩이 단일 연산 성능에서는 엔비디아에 다소 못 미칠 수 있지만, 대량 병렬 연결과 네트워킹 성능을 기반으로 전체적인 시스템 성능을 끌어올렸다는 것이 핵심이에요. 🚀
중국 내수 시장에서는 이 칩을 활용한 다양한 기업용 솔루션이 등장하고 있고, 최근에는 아프리카, 동남아시아 시장으로도 진출을 확대 중이에요. 하드웨어뿐 아니라 AI 생태계 전체를 패키지로 공급하고 있다는 점이 주목할 만해요.
🎯 단일 칩 이상의 전략, 화웨이 AI의 실체는?
👇 바로 아래에서 더 깊이 있는 비교 확인해보세요!
📊 엔비디아 GB200과의 성능 비교
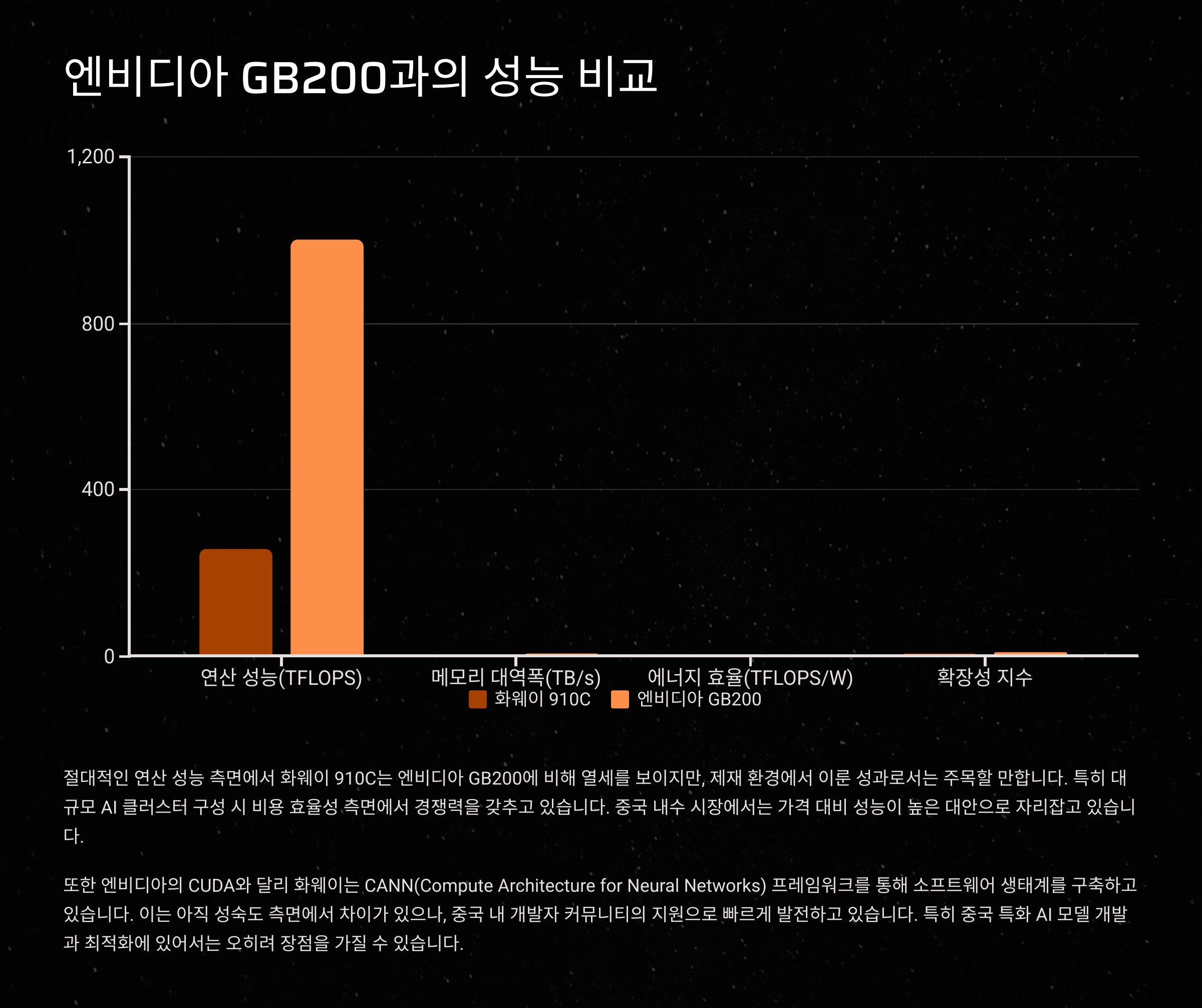
화웨이의 ‘클라우드 매트릭스 384’는 어센드 910C 1184개를 연결해 만든 거대한 AI 서버예요. 이와 맞붙는 상대는 엔비디아의 GB200 Grace-Blackwell 슈퍼칩이에요. 이 칩은 Grace CPU와 Blackwell GPU가 통합된 형태로, 엔비디아가 공개한 최신 AI 서버 플랫폼이죠.
단일 칩 기준으로 보면 엔비디아 GB200은 2500TFLOPS에 달하는 연산 능력을 자랑하며, HBM3 192GB 메모리를 사용해 높은 대역폭을 확보하고 있어요. 반면 어센드 910C는 약 800TFLOPS 수준의 성능이고 HBM2E 128GB 메모리를 탑재하고 있어요. 스펙상으로는 분명 엔비디아가 앞서죠.
하지만 전체 시스템 성능으로 넘어가면 이야기가 달라져요. 화웨이의 시스템은 무려 384개의 칩을 병렬 연결하며, 이들을 고속 통신으로 엮는 자체 인터커넥트 기술 ‘클라우드 링크’와 14개의 광 트랜시버를 활용해 효율적인 데이터 전송을 실현했어요. 덕분에 전체 성능은 엔비디아보다 2배 이상 높은 수준으로 평가받고 있어요.
전력 소모 측면에서는 화웨이가 더 많은 전력을 요구하지만, 중국의 에너지 정책 상 효율보다는 성능이 우선이기 때문에 실사용에 큰 장애가 되지 않는다는 분석도 있어요. 이처럼 성능을 확장하는 스케일 아웃 전략에서 화웨이는 놀라운 설계력을 보여준 셈이에요.
⚖️ 주요 성능 비교표
| 항목 | 화웨이 CloudMatrix 384 | NVIDIA GB200 Grace-Blackwell |
|---|---|---|
| 총 연산성능 | 180 PFLOPS 이상 | 90 PFLOPS |
| HBM 총 용량 | 49.2 TB | 13.8 TB |
| 통신 인터페이스 | CloudLink (광 트랜시버) | NVLink 5.0 / Infiniband |
| 전력 소모 | 약 4배 많음 | 상대적으로 낮음 |
이처럼 단순 수치로는 비교가 어렵지만, 전체 구성과 활용 전략에 따라 화웨이의 시스템도 무시할 수 없는 수준임을 보여주고 있어요. 실제로 AI 트레이닝 작업에서는 병렬성과 네트워크 구조가 훨씬 중요하다는 점도 이런 평가를 뒷받침해줘요. 💥
특히 GPU 단일 성능이 아닌, AI 데이터센터 전체의 연산 구조를 고려해야 하는 요즘의 AI 패러다임에서는 화웨이의 시스템적 접근이 경쟁력이 될 수 있답니다.
🧩 단일 성능? 시스템 전략? 당신의 선택은?
👇 전체 아키텍처 흐름을 이해하고 싶다면 지금 확인하세요!
🔌 네트워크 기술과 통신 구조
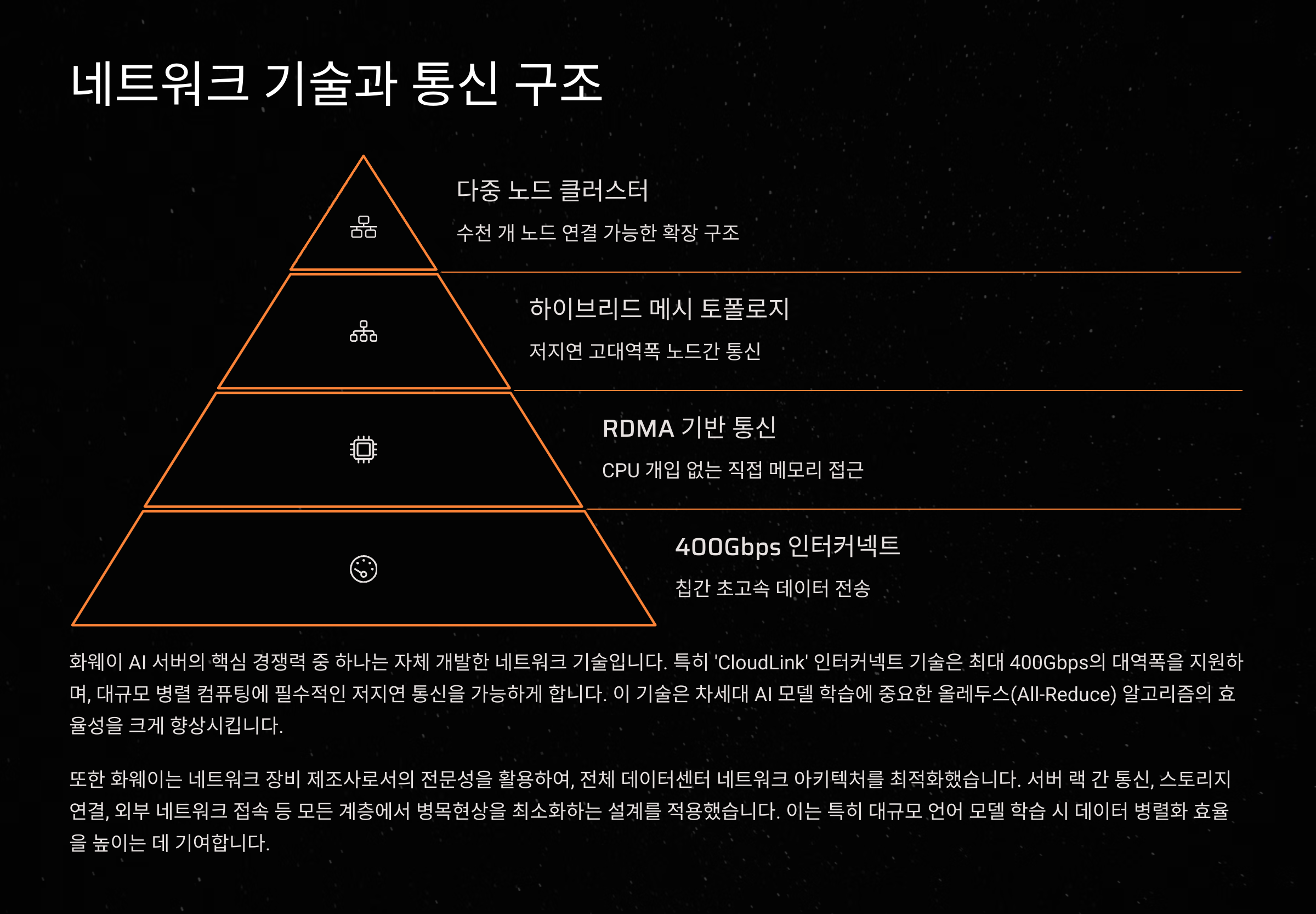
AI 서버의 진정한 경쟁력은 단순히 연산 성능에만 있지 않아요. 칩 수십 개, 수백 개를 병렬 연결해도 그 사이의 데이터 전송 속도가 느리면 전체 시스템 성능은 반감되거든요. 그래서 화웨이는 전통적인 강점인 ‘네트워크’ 기술을 활용해 자신만의 경쟁력을 확실히 드러냈어요.
화웨이는 ‘클라우드 링크 인터커넥트(CloudLink Interconnect)’라는 독자 인터페이스를 도입했어요. 이는 각 AI 칩을 서로 빠르게 연결해주는 초고속 통신 기술로, 엔비디아의 NVLink 5.0이나 인피니밴드와 같은 역할을 수행하죠. 특히 이 구조는 각 서버 랙 간, 그리고 칩 간의 올투올(All-to-All) 통신 구조를 지향해요.
이 시스템에서는 한 개의 어센드 910C 칩당 무려 14개의 광 트랜시버가 장착돼 있어요. 광 트랜시버는 기존의 구리선을 사용하는 전송 방식보다 간섭이 적고, 속도가 빠르며, 더 멀리까지 안정적으로 데이터를 전송할 수 있는 장점이 있죠. 이러한 기술 덕분에 화웨이는 칩 간 통신 병목을 크게 줄일 수 있었어요.
또한 내부 통신에서는 로우 레이턴시(Low Latency)를 유지하면서도, 외부 통신에서는 높은 대역폭을 확보하고 있어요. 이것은 대규모 트랜스포머 모델을 학습하거나 추론하는 데 있어 매우 중요한 요소예요. 데이터가 수백 테라바이트를 오가야 하는 AI 모델에서 이 정도 통신 구조는 필수죠.
🔗 통신 구조 핵심 요약
| 요소 | 설명 |
|---|---|
| CloudLink | 화웨이 독자 인터커넥트 기술, 올투올 구조 지향 |
| 광 트랜시버 | 칩당 14개 탑재, 빠른 데이터 송수신 가능 |
| 내부 통신 구조 | 초저지연, 고대역폭 네트워크 구성 |
| 확장성 | 수평적 스케일아웃 구조에 최적화 |
이런 네트워크 역량은 단순히 칩을 많이 묶는 기술이 아니라, ‘효율적으로 연결하고 빠르게 전달하는 설계력’을 필요로 해요. 바로 이 부분이 화웨이의 진짜 무기이자, 네트워크 장비 분야의 오랜 노하우가 집약된 결과예요. 🛰️
참고로, 이러한 통신 구조는 AI 서버뿐만 아니라 클라우드 컴퓨팅, 엣지 컴퓨팅 등 다양한 분야에도 적용 가능해서 화웨이의 AI 인프라 확장에 유리한 발판이 되고 있어요. 칩과 네트워크의 유기적 통합, 바로 이게 시스템 경쟁력의 본질이랍니다!
🌐 AI 인프라의 핵심은 통신이다!
👇 네트워크 기술의 승부처, 지금 확인해보세요!
💧 액체 냉각과 전력 소모

AI 서버는 엄청난 전력을 소모하고, 동시에 어마어마한 열을 발생시켜요. 기존의 공랭 방식, 즉 팬으로 바람을 불어넣는 방식으로는 이 열을 감당하기 어려운 상황이 생긴답니다. 그래서 최근 고성능 서버에는 ‘액체 냉각’ 기술이 도입되고 있어요.
화웨이도 이번 ‘클라우드 매트릭스 384’ 서버에 ‘다이렉트 칩 리퀴드 쿨링’ 시스템을 적용했어요. 이건 말 그대로 칩 표면에 액체 냉각기를 직접 연결해, 열을 빠르게 외부로 전도시키는 방식이에요. 공기보다 액체가 열전도율이 훨씬 높기 때문에 훨씬 효율적인 냉각이 가능하죠.
또한 이 방식은 서버 랙의 밀도가 높아지더라도, 안정적으로 냉각이 가능하게 해줘요. 실제로 이 서버에는 16개의 랙이 있고, 랙마다 32개의 GPU가 들어가 있어요. 이런 초밀집 구조에서는 액체 냉각이 거의 필수적이에요. 아니면 열 때문에 서버가 다운되거나, 성능이 저하될 수도 있거든요.
물론 액체 냉각 시스템을 운영하려면 추가적인 냉각 유닛, 펌프, 튜브 등이 필요하고, 전력 소모도 더 발생해요. 하지만 화웨이의 전략은 “성능을 극대화하는 것이 먼저”예요. 중국은 전력 단가가 낮고, 재생 에너지를 대규모로 활용하기 때문에 이런 전략이 가능한 거예요.
🧊 냉각 시스템 비교표
| 냉각 방식 | 설명 |
|---|---|
| 공랭식 (Air Cooling) | 팬을 통해 공기 흐름으로 냉각, 효율 낮음 |
| 수랭식 (Liquid Cooling) | 칩에 직접 냉각 유체를 접촉, 효율 매우 높음 |
| 화웨이 적용 | Direct-to-chip 액체 냉각 방식 채택 |
중국은 석탄 중심의 전통 에너지 외에도 태양광, 풍력, 수력 같은 재생에너지 투자도 활발해요. 실제로 지난 10년간 미국 전체 에너지 생산량과 맞먹는 수준의 전력 인프라를 확장해왔고, AI 데이터 센터 운영에도 넉넉한 에너지 자원이 뒷받침돼요.
결국 화웨이의 서버 설계 철학은 “절전보단 퍼포먼스”예요. 이는 서구 기업들이 중요시하는 ‘전성비(Watt당 성능)’와는 다른 전략이지만, 에너지 상황이 다른 중국에게는 현실적이고 효과적인 방식이에요. ⚡
🌡️ 열 잡고, 성능 높이는 핵심은?
👇 서버 냉각의 진화, 직접 확인해보세요!
🌏 중국 반도체의 자립과 의존
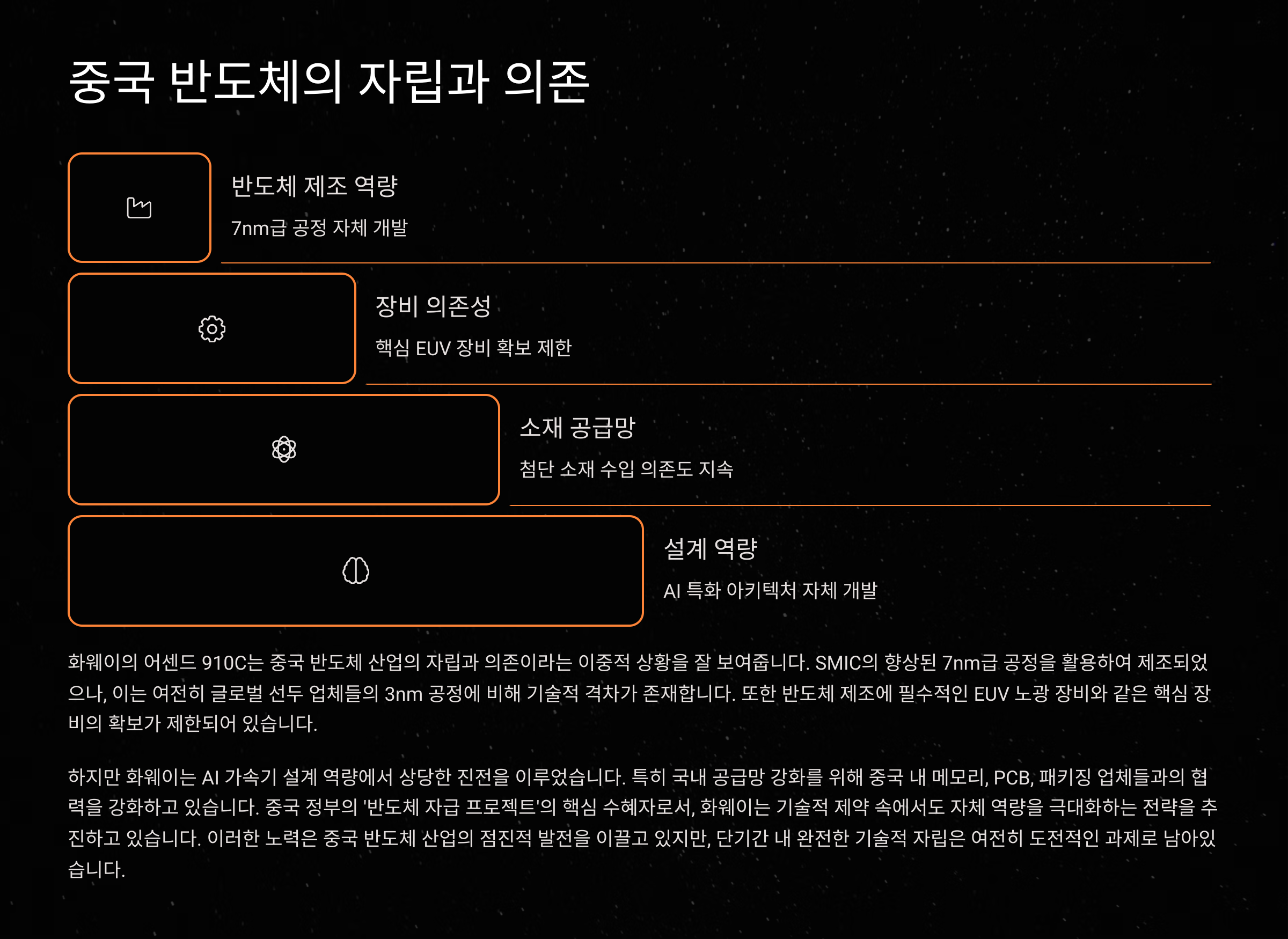
화웨이의 AI 칩이 자국 내에서 모두 제조되고 있다고 생각한다면, 그건 아직은 반쪽짜리 진실이에요. 어센드 910C는 중국 SMIC(중신국제반도체)에서 일부 생산되긴 하지만, 많은 경우 대만의 TSMC에서 제조된다는 분석도 있어요.
특히 칩의 성능을 결정짓는 주요 공정인 7nm 기술은 TSMC가 글로벌 최상급을 유지하고 있죠. 실제로 세미어낼리시스의 리포트에 따르면, 어센드 910B와 910C 다이(칩 내부 회로)를 분석한 결과 TSMC에서 생산된 흔적이 뚜렷하다고 해요. 미국의 제재가 있음에도 이뤄진 일이죠.
또한 고속 메모리인 HBM(High Bandwidth Memory)의 경우도 대부분 삼성전자나 SK하이닉스에서 공급을 받아온 것으로 나타났어요. 실제로 제재 이전에 1300만 개 이상의 HBM2E 스택을 선제적으로 확보한 것으로 알려져 있고, 이를 AI 서버 구축에 활용하고 있어요.
중국은 동시에 자립을 위한 내부 기술 투자도 아끼지 않고 있어요. 창신메모리(ChangXin Memory Technologies)와 YMTC 같은 기업들이 점차 성장하고 있으며, HBM과 DDR5 메모리 자체 생산도 머지않았다는 전망이 나오고 있어요. 하지만 아직까지는 주요 부품의 해외 의존도가 높은 것도 사실이에요.
🔍 중국 반도체 공급 현황 요약
| 부품 | 공급 기업 | 특이사항 |
|---|---|---|
| AI 칩(910C) | TSMC, SMIC | TSMC 기반 7nm 공정 활용 추정 |
| HBM 메모리 | 삼성, SK하이닉스 | 제재 전 확보, 현재 재고 사용 중 |
| 광 트랜시버 | 중국 현지 네트워크 업체 | 자체 설계 비중 확대 중 |
중국의 기술 굴기는 ‘단절’이 아니라 ‘연결’을 통해 성장하고 있어요. 필요한 부분은 글로벌 소스를 최대한 확보하면서, 동시에 내부 생태계를 빠르게 따라잡아 가는 전략이에요. 이는 장기적으로 자립을 위한 브릿지(교량) 역할을 해주는 거죠.
결국 완전한 독립보다는 “하이브리드 의존도 감소”가 현실적인 목표라는 거예요. AI 기술 패권 경쟁 속에서 중국은 필요한 건 빠르게 사들이고, 내부에서 대체하려는 ‘투 트랙’ 전략을 택하고 있다는 걸 이해할 필요가 있어요. 🧱
🔋 중국산 칩, 정말 '중국산'일까?
👇 반도체 공급망의 숨겨진 진실을 지금 확인하세요!
🔭 기술 경쟁에서의 전략적 시사점

화웨이의 AI 서버 행보는 단순히 하나의 기업이 기술 발전을 이루었다는 의미를 넘어서, 글로벌 AI 패권 전쟁의 새로운 국면을 보여줘요. 중국은 제재 속에서도 엄청난 시스템을 만들어내며, 단순한 기술 추종이 아닌 독자 생태계를 만들고 있다는 점에서 매우 주목할 필요가 있어요.
이제는 단일 칩의 성능 경쟁을 넘어서, 얼마나 많은 칩을 얼마나 효율적으로 연결하고 통합할 수 있는지가 중요해졌어요. 화웨이는 네트워크, 메모리, 냉각, 통신 구조, 심지어 자체 인터커넥트까지 하나의 통합 시스템으로 완성하고 있어요. 이건 기술력 이상의 전략이기도 해요.
우리나라 입장에서 보면, 메모리 산업만으로는 AI 중심 시대에서 주도권을 유지하기 어려워질 수도 있어요. 엔비디아처럼 GPU 생태계를 갖추거나, 화웨이처럼 토탈 시스템 아키텍처를 갖추는 방향으로의 전략적 변화가 요구돼요.
또한 중요한 점은, 적이나 경쟁자의 기술을 정확히 분석하고 직시해야 한다는 점이에요. 중국이 기술적 한계를 극복하고 있다는 점을 외면하거나 과소평가해서는 안 돼요. 오히려 이를 인정하고, 더 나은 방향으로 정책, 투자, 기술개발을 강화하는 것이 필요한 때예요.
🧭 전략적 시사점 요약
| 시사점 | 내용 |
|---|---|
| 패러다임 전환 | 단일 칩 경쟁 → 시스템 전체 설계 경쟁 |
| 산업 연계성 | 네트워크·메모리·냉각 등 전방위 기술 통합 필요 |
| 정책 방향 | 자립 기술 투자 및 생태계 설계 중심의 R&D 강화 |
AI는 더 이상 소프트웨어만의 전쟁이 아니에요. 하드웨어부터 시작해 전체 구조를 설계하고, 연결하고, 냉각하고, 운영하는 총체적 인프라 구축이 핵심이에요. 그리고 이 인프라를 얼마나 전략적으로 확장할 수 있느냐가 앞으로 AI 강국을 결정짓는 요소가 될 거예요. 🚀
화웨이는 기술적, 정책적, 전략적 모든 측면에서 이를 빠르게 따라잡고 있는 모습이에요. 우리는 이를 경계할 대상이 아니라, 학습의 대상으로도 삼아야 한다고 생각해요.
📌 AI 시대, 당신의 전략은 무엇인가요?
👇 아래에서 전략적 인사이트를 직접 확인해보세요!
❓ FAQ

Q1. 화웨이 어센드 910C는 어떤 칩이에요?
A1. 화웨이 어센드 910C는 AI 학습 및 추론에 특화된 칩으로, BF16 연산 기준 약 512TFLOPS의 성능을 자랑해요. 대규모 AI 모델 학습에 활용되고 있어요.
Q2. 클라우드 매트릭스 384 시스템은 무엇인가요?
A2. 화웨이가 어센드 910C 1184개를 병렬로 연결해 만든 초대형 AI 서버 시스템이에요. 전체 성능은 엔비디아 GB200 시스템보다 높다고 평가돼요.
Q3. GB200과 비교하면 어떤 점이 달라요?
A3. 단일 칩 성능은 GB200이 우세하지만, 화웨이는 더 많은 칩을 네트워크로 엮어 전체 시스템 성능을 끌어올렸어요. 시스템 설계와 네트워킹이 강점이에요.
Q4. 화웨이는 자체적으로 칩을 생산하나요?
A4. 일부는 SMIC에서 생산되지만, 여전히 TSMC의 7nm 공정을 이용한 것으로 알려졌어요. 완전한 자립은 아직 아니에요.
Q5. 왜 광 트랜시버를 사용하는 거죠?
A5. 광 트랜시버는 속도가 빠르고, 간섭이 적으며, 대량의 데이터를 빠르게 전송할 수 있기 때문이에요. AI 서버에서는 필수예요.
Q6. 냉각 방식은 어떻게 되나요?
A6. Direct-to-chip 액체 냉각 방식으로, 고밀도 서버에서 발생하는 열을 효율적으로 제거할 수 있어요.
Q7. 중국은 반도체 자립이 가능한가요?
A7. 현재는 해외 의존도가 남아있지만, SMIC, CXMT 등 로컬 기업들이 빠르게 발전 중이에요. 몇 년 내 상당한 수준의 자립이 가능할 것으로 보여요.
Q8. 이 기술이 한국에 주는 의미는?
A8. 단순 메모리 제조에 그치지 않고, 시스템 전체를 설계하고 운영할 수 있는 기술력과 전략이 중요해졌다는 의미예요. 기술 패권 전쟁은 ‘통합력’ 싸움이에요.
세계 최초 만질 수 있는 홀로그램 혁명
📋 목차홀로그램 기술의 기원과 진화삼성과 글로벌 연구진의 도전플렉시볼 기술의 핵심 원리사용자 반응과 실제 구현 사례한국 기술의 현재와 도전 과제홀로그램의 미래 전망FAQ🌐 손으로 만
sugar-family.tistory.com
📌 애드센스 수익을 높이는 최적 광고 위치 전략
📋 목차💡 애드센스 광고의 기본 원리📍 첫 화면(Top Fold) 광고 위치📰 본문 중간 광고 배치 전략📐 사이드바와 위젯 광고 활용📱 반응형 광고의 중요성과 설정👀 사용자 행동 기반 위치 최
sugar-family.tistory.com
🚀오픈AI O4 미니 성능 완전 분석!
📋 목차🧠 O4 미니와 O3의 등장 배경⚙️ AI 시스템과 툴의 진화📊 벤치마크 성능 비교🤖 AI 자동화 시대의 활용법🎨 아스키 아트 실시간 변환 데모💸 O4 미니의 경제적 가치📈 AI 활용의 미래
sugar-family.tistory.com